Our Data Science team at Bolt consists of talented data scientists and machine learning engineers who are the driving force behind our advanced analytics, production machine learning models, and the experimentation engine that powers Bolt’s decision-making.
At Bolt, data scientists own their models and optimisation algorithms.
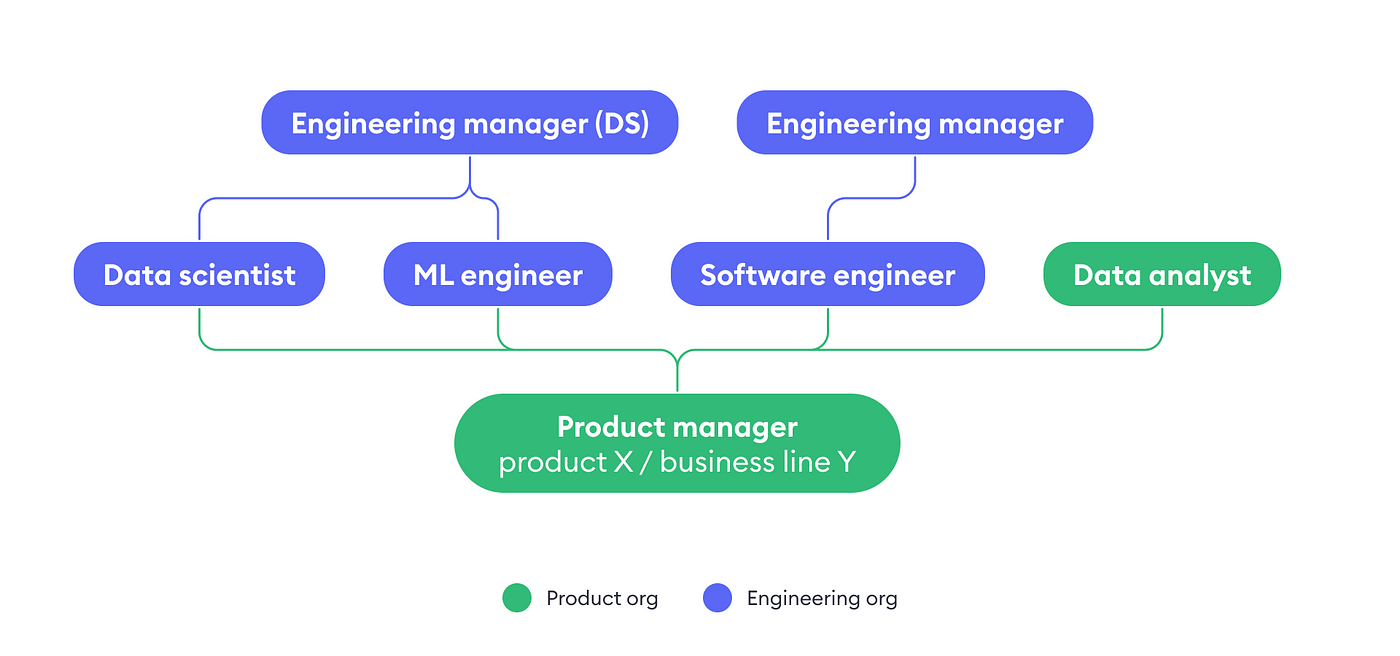
This is a challenging feat and requires some software engineering skills. Hence, data scientists are a part of the Engineering division, and we also look for people who can write the necessary code and own and deliver the projects.
At Bolt, our approach to data science may differ from other big tech companies. While they may prioritise analytics and experimentation, we rely on our talented product data analysts to stay informed and drive our global expansion and operations.
Work and personal growth
Our work is completed in cross-functional teams consisting of software engineers, product managers, and data analysts, all focused on optimising common KPIs. However, as data science work is iterative and experimental in nature, it operates differently from regular software teams.
Typically, the process begins with product management brainstorming ideas followed by exploring data and testing initial concepts using past data. The next steps involve training, deploying, and monitoring models worldwide across all markets.
We encourage our colleagues to continue learning due to the iterative and experimental nature of the work. Therefore, we:
Schedule regular discussions about the latest projects, papers, or methodologies;
Encourage the exchange of feedback and reviews, including design documents, pull requests, and workshops, among individuals who work on separate product teams;
Host a learning club where past sessions have covered topics such as operations research, reinforcement learning, causal inference, and deep learning.
Our team of Model Lifecycle engineers has developed a platform that streamlines the process of training and deploying ML models. With this platform, you can take a well-structured Jupyter notebook’s code into production within just a few days (after removing Pandas from the inference part, of course).
Tech stack
At Bolt, a data scientist will become accustomed to dockerising their Python code, utilising Airflow and Jenkins to manage its execution, and tracking model lineage through Amazon SageMaker. To make sense of the model results, a combination of Great Expectations, Grafana, and our in-house A/B test analysis engine is utilised. Python microservices are the preferred method of model deployment to avoid any integration issues with other teams.
Our team of data scientists and machine learning engineers handles every aspect of an applied project. They begin by identifying a product problem and developing a technical solution. Then, they gather the necessary source data and create a prototype using a notebook-like environment. They refine the prototype and ultimately deploy it to production.
Many data science projects make use of machine learning methods, like gradient boosted tree ensembles, time series forecasting, deep learning and reinforcement learning. However, some issues may pertain to causal inference from observational data or constrained optimisation.
Therefore our team consists of individuals with diverse profiles, including mathematicians, computer scientists, AI specialists, physicists, signal processing engineers, and even economists.

.png)


